So, here we go again – I’ve said it once, so I’ll say it again. It gives me no pleasure to write another blog post about AWS suffering another outage in their West Virginia Zone. This because of a couple of reasons: First, the publicity – industry analysts and commentators are divided into two camps, some taking the view that AWS is slightly unfit for the purpose (Barb Darrow from Gigaom: “Cloud outage raises more questions about Amazon Cloud” ) and others taking the more pragmatic view that Instagram, Netflix, etc. (AWS customers) could have been more proactive in protecting themselves against their host going offline (Ingrid Lunden from TechCrunch: “Could Instagram and other sites avoid going down with Amazons Ship”)
The twitter feed kicked in on Saturday morning after the outage on Friday night, and when I saw the first few tweets coming in, I thought it was just people catching up and re-posting regarding the previous AWS issue only two weeks before. But no; it was groundhog day all over again – storm hits; power cut; generators didn’t work; elastic cloud falls over; sites go down!
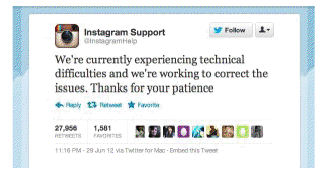
Checking the hash tags for #Netflix, #Instagram, #AWS and #AWSoutage, I saw all the expected reactions – AWS customers posting stuff like this:
Nearly 28,000 re-tweets, and similar for NetFlix, Pinterest, and Heroku.
The publicity for all of these companies is clearly not good – consumers don’t care or even know what a “host” is. Unless you work in IT, why would you care or want to know? To a consumer, the service they either pay for (Netflix) or use on an hourly basis (Instagram) just doesn’t work, and that type of damage is difficult to undo.
The second reason is that it just gives more fuel to the “I told you so” cloud naysayers. You can just hear old-school CIOs whispering to fearful CEOs all over the world, “the cloud is not ready for us, and we’re certainly not ready for it!”
But I feel I’m repeating myself a bit from my last post, so let’s move on and take an alternate view, one which I subscribe to, and one that infrastructure teams at Netflix et al. would do well to explore.
Putting all your eggs in one basket is clearly a strategy that is both good and bad; good, because you get to be a big customer of a provider; you get economies of scale, better pricing, and someone should pick the phone up when you call, etc., etc., but bad, because you give away some control. When AWS went down, it is clear that many infrastructure teams at customer sites who may have engineered their application to be redundant inside their host didn’t take into account the unthinkable – what happens if the host goes down?
As Michael Lee from ZDNet pointed out in a post on 2 July, quoting Intelligent Business Research Services advisor Jorn Bettin, the blame for the outage may have lain with providers failing to utilise cloud services as they should.
He said that the real issue wasn’t that such a huge cloud-services giant such as Amazon had stumbled over a storm, but that the affected customers – Instagram, Pinterest, Pocket and Netflix (which all suffered from Amazon’s recent outage on the weekend) – hadn’t used the ability of the cloud to create geographically redundant links.
“They could operate at a higher level of redundancy, so that these sort of outages would only have a minimal impact on them. It’s a matter of cost,” Bettin said.
This is the most sensible article I’ve read about the AWS outage issue thus far. Having one provider manage your entire infrastructure without a DR/Back-up strategy with another cloud provider is just commercial madness.
Now, I understand there is a cost element here – the cost of replicating some or all of your infrastructure to spin up when a disaster happens is expensive, isn’t it?
Well, yes and no.
Yes, it’s going to add some level of cost, but what you gain from that is control. You, the System Admin from Pintflixogram, get control to the extent that if your primary host goes down, you get to fire up another, secondary host and maintain your service. Let’s remember AWS is not the only hosting company on the planet. Although they may be perceived as such by many, but in fact there are plenty of regional outfits in the market that are not as cheap as AWS. But guess what – they don’t go down.
On the other hand, if you balance the reputational risk, the customer support calls you have to field, the tickets raised, the PR damage limitation exercise and, finally, the churn as your customer base leaves for your competitor, then no, it’s not expensive.
Companies seem to forget that the quality of hosting service you use is the public perception of your company. You can have the coolest website, the best marketing machine, an awesome product or service, but it all counts for nothing when your customer see’s this:
I can only imagine the frustration and sense of helplessness that the PR folks and the system admins felt, as there is literally nothing they can do to get their service up online until their host tells them they are back up online.
But if they had explored a strategy whereby the client had the control instead of the host, then it could have been service as normal.
AWS are getting hammered, which is understandable from a certain perspective – clients frustrated that their site has gone down; everyone in the space commenting that this shouldn’t happen – but really, the larger clients of AWS who could and should have explored “Redundancy across Regions” (RaR) strategies only have themselves to blame. There is not an industry on the planet that does not have some kind of back-up plan to maintain their core business in the event of a natural disaster, be it as simple as work from home, or a complete replication of their business environment somewhere else.
It’s clear here that some companies had no such plan and just blamed their host, when in fact, if you look at the big picture, it was their own fault. Murphy’s Law exists for a reason, and there are lessons to be learned here.
It’s very simple: You pay for what you get; you pay for greater control and security so that in the event of something bad happening, you don’t have a ground-hog day, and you also beat Murphy at his own game.
By Jason Currill
Jason Currill is a seasoned Executive with over 20 yearsʼ international sales and sales leadership experience in investment banking and information technology. In 2011 he founded Ospero, a global Infrastructure as a Service (IaaS) company. Prior to founding Ospero, he held leadership positions at Cisco Systems, Business Objects (an SAP company) and NetSuite, running both EMEA and NA theaters. In addition, Jason spent 10 years as a leading Futures Trader in the London International Financial Futures Exchange (LIFFE) for SG Warburg, Nomura and ING Bank.