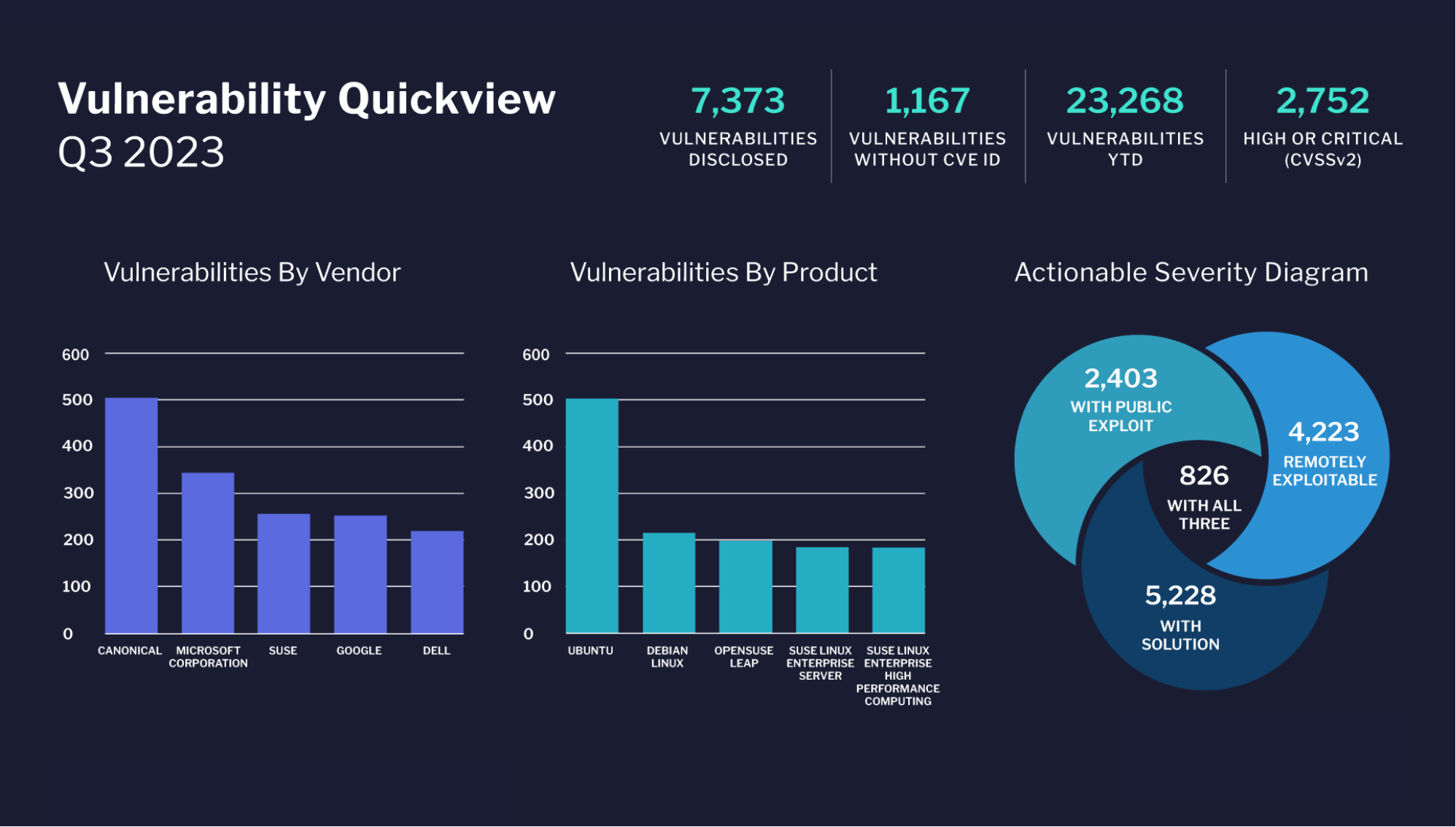
Data mining techniques come in two main forms: supervised (also known as predictive or directed) and unsupervised (also known as descriptive or undirected). Both categories encompass functions capable of finding different hidden patterns in large data sets.
Although data analytics tools are placing more emphasis on self service, it’s still useful to know which data mining operation is appropriate for your needs before you begin a data mining operation.

(Infographic Source: New Jersey Institute of Technology)
Supervised data mining techniques are appropriate when you have a specific target value you’d like to predict about your data. The targets can have two or more possible outcomes, or even be a continuous numeric value (more on that later).
To use these methods, you ideally have a subset of data points for which this target value is already known. You use that data to build a model of what a typical data point looks like when it has one of the various target values. You then apply that model to data for which that target value is currently unknown. The algorithm identifies the “new” data points that match the model of each target value.
Now let’s clarify that with some specific demonstrations:
As a supervised data mining method, classification begins with the method described above.
Imagine you’re a credit card company and you want to know which customers are likely to default on their payments in the next few years.
You use the data on customers who have and have not defaulted for extended periods of time as build data (or training data) to generate a classification model. You then run that model on the customers you’re curious about. The algorithms will look for customers whose attributes match the attribute patterns of previous defaulters/non-defaulters, and categorize them according to which group they most closely match. You can then use these groupings as indicators of which customers are most likely to default.
Similarly, a classification model can have more than two possible values in the target attribute. The values could be anything from the shirt colors they’re most likely to buy, the promotional methods they’ll respond to (mail, email, phone), or whether or not they’ll use a coupon.
Regression is similar to classification except that the targeted attribute’s values are numeric, rather than categorical. The order or magnitude of the value is significant in some way.
To reuse the credit card example, if you wanted to know what threshold of debt new customers are likely to accumulate on their credit card, you would use a regression model.
Simply supply data from current and past customers with their maximum previous debt level as the target value, and a regression model will be built on that training data. Once run on the new customers, the regression model will match attribute values with predicted maximum debt levels and assign the predictions to each customer accordingly.
This could be used to predict the age of customers with demographic and purchasing data, or to predict the frequency of insurance claims.
Anomaly detection identifies data points atypical of a given distribution. In other words, it finds the outliers. Though simpler data analysis techniques than full-scale data mining can identify outliers, data mining anomaly detection techniques identify much more subtle attribute patterns and the data points that fail to conform to those patterns.
Most examples of anomaly detection uses involve fraud detection, such as for insurance or credit card companies.
Unsupervised data mining does not focus on predetermined attributes, nor does it predict a target value. Rather, unsupervised data mining finds hidden structure and relation among data.
The most open-ended data-mining technique, clustering algorithms, finds and groups data points with natural similarities.
This is used when there are no obvious natural groupings, in which case the data may be difficult to explore. Clustering the data can reveal groups and categories you were previously unaware of. These new groups may be fit for further data mining operations from which you may discover new correlations.
Frequently used for market basket analysis, association models identify common co-occurrences among a list of possible events. Market basket analysis is examining all items available in a particular medium, such as the products on store shelves or in a catalogue, and finding the products that are commonly sold together.
This operation produces association rules. Such a rule could be a statement declaring “80 percent of people who buy charcoal, hamburger meat, and buns also buy sliced cheese,” or, in a less “market basket” style example, “90 percent of Detroit citizens who root for the Tigers, the Lions, and the Pistons also favor the Red Wings over other hockey teams.”
Such rules can be used to personalize the customer experience to promote certain events or actions. This can be accomplished by organizing store shelves with associated items nearby, or by tracking customer movements through a website in real time to present them with relevant product links.
Feature extraction creates new features based on attributes of your data. These new features describe a combination of significant attribute value patterns in your data.
If violence, heroism, and fast cars were attributes of a movie, then the feature may be “action,” akin to a genre or a theme. This concept can be used to extract the themes of a document based on the frequencies of certain key words.
Representing data points by their features can help compress the data (trading dozens of attributes for one feature), make predictions (data with this feature often has these attributes as well), and recognize patterns. Additionally, features can be used as new attributes, which can improve the efficiency and accuracy of supervised learning techniques (classification, regression, anomaly detection, etc.).
Knowing your goals and the appropriate techniques to achieve them can help your data mining operations run smoothly and effectively. Different data is appropriate for different insight and understanding what you’re asking from your data analysts expedites the process for everyone.
By Keith Cawley