
For good reason there is a lot of discussion about multi-cloud among enterprise data architects, CIO/CDOs, industry analysts and tech illuminati. But what is multi-cloud? The term suffers from ambiguity and misunderstanding that often plague emerging technology architecture concepts.
We’re best to understand what multi-cloud is (and isn’t) in the frame of the “pain” multi-cloud should solve. The term “multi-cloud” is most commonly associated with the proposition of escaping cloud vendor lock-in and the challenges that stem from lock-in. As we’ve written in the post, Reframing Lock-in In the Era of Data-Driven Transformation, we subscribe to a “data-gravity” version of lock-in where the main “problem” is the difficulty in making data available to the cloud applications, native and third-party data services offered by cloud providers.
If today’s version of cloud vendor lock-in is about data – specifically making data available to applications, and native and third-party data services in the cloud – then multi-cloud must be a data-centric solution that solves for the challenges of making data available to the right applications and services anytime and anywhere.
Common practice among organizations who are already using applications and services in multiple clouds is to copy and move data so that data resides in each of the clouds in which the organization is hosting applications and using services.
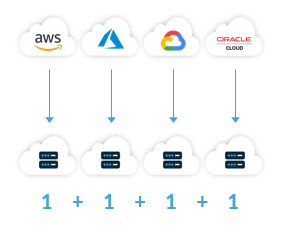
It would be a misnomer to refer to this “application-first” approach to solving data gravity as multi-cloud. Rather, this approach is best understood as a multiple cloud approach. Typical pain points that stem from a multiple cloud approach to making data available to applications and services in multiple public clouds include:
All of these challenges can impede the progress of data-driven transformation initiatives resulting in a business ceding advantage to competitors with more nimble data architectures.
Although there exists software that can facilitate the duplication and synchronization of data across multiple public clouds, it remains operationally difficult, costly and time consuming, and in some cases impractical to do so, particularly with large data sets. This is a matter of physics; with the speed of light being a rate-limiting factor complicated by security, governance, compliance and other factors.
Multiple cloud approaches to solving for data gravity emerge from an antiquated application-level view of lock-in, where the location of the application determines the location of the data. If we reframe our view of lock-in as a data-gravity problem, we’re liberated to re-imagine the solution; shifting from an application-first view to a data-first view.
What is required to solve data gravity is a data-first architecture for the public cloud. Such a solution would enable a one data store to present data to applications, and native and third-party data services in multiple clouds simultaneously. In a data-first architecture, each application and service could read and write to the same data set, simultaneously. Such an architecture requires a combination of cloud-adjacent data and networking to present that data into applications and services in multiple clouds.
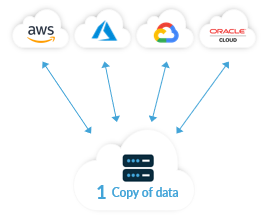
This data-first concept of the solution to data-gravity is truly multi-cloud by design with one copy of data attached to applications and services in multiple public clouds (including multiple availability zones) simultaneously.
It is particularly critical and urgent for IT organizations to solve the challenges of data gravity in the era of data-driven transformation where the inability to make data readily available can leave an organization falling behind its competitors. Enabling data-driven transformation requires re-imaging cloud architecture with a solution that defies data gravity by presenting data to applications and services in multiple public clouds rather than moving data to where applications and services reside. In making this shift from application-centric cloud design principles to data-first cloud design principles, it becomes obvious with the benefit of hindsight that a true multi-cloud data architecture is an enabler of data-driven business transformation.
By Derek Pilling







