Cloud computing has been a boon to big data processing. The ability to capture, store, and process data without having to worry about scaling servers and databases has democratized and advanced big data capabilities like never before.
At the same time, the Internet of Things (IoT) industry has grown immensely. And with more and more IoT devices creating an exponentially increasing amount of data, the need to process and analyze this data faster is growing.
While the cloud is crucial to the success of IoT, under certain circumstances, cloud computing alone can’t meet these demands for faster data analysis.
Enter edge computing.
In this article, we’ll discuss what edge computing is, in what situations it is best applied, and how edge and cloud computing work together.
Edge computing entails processing and analyzing data closer to the source of where that data is collected.
Instead of a device or sensor sending all of its data over the internet to the cloud or an on-premise data center, it can:
With this new kind of architecture, a vast amount of processing power becomes decentralized from cloud Service Providers, which can help increase the speed of data analysis and decrease the load placed on internet networks to transmit huge amounts of data.
Business Insider expects that over 5.6 billion devices will utilize edge computing, primarily in the manufacturing, energy, and transportation industries.
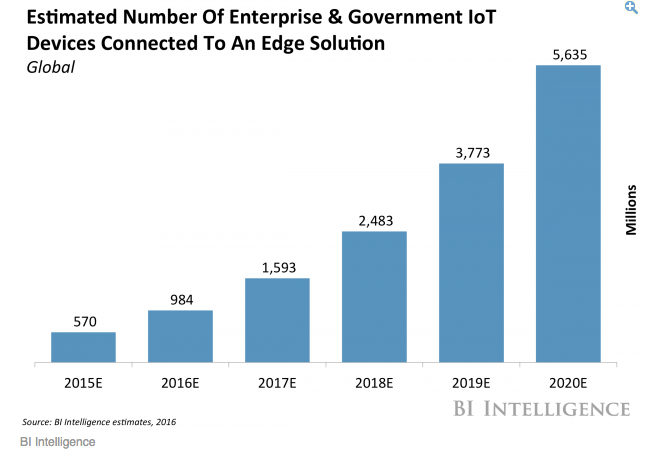
Huge growth of IoT devices. Courtesy of Business Insider
Mobile network operator AT&T is making a big bet on edge computing, as is competitor Verizon.
And the OpenFog Consortium was formed by various tech companies and academic institutions to create standards and promote edge and fog computing across industries.
Whether you’re in manufacturing, transportation, energy, or another industry, the use of smart devices and sensors to collect data from machines, vehicles, or people’s smartphones can have a big impact on your business. And edge computing can help you better analyze and manage all of the valuable data these devices generate.
Edge computing solves a few problems related to the transfer of data for IoT technologies, including latency, reduced load on networks, privacy and security, reduced data management costs, and disaster recovery.
The first problem that edge computing solves is latency – how long it takes to process and analyze the captured data.
The prototypical example of the use of edge computing to reduce latency is driverless cars.
Waymo, Google’s autonomous vehicle company, estimates that its self-driving cars produce 1GB of data per second. 1GB every second!
That’s an insane amount of data. And a lot of it has to be analyzed very quickly so the autonomous vehicle can assess where it needs to go and how to avoid smashing into another car.
Imagine the car’s sensors collect the data and send it to the cloud for processing. Then the cloud processes and analyzes the data and sends back the insights to the sensors so the car can react to its surroundings.
Even if this all occurs within a few seconds, it still wouldn’t be fast enough, and that Ford Taurus parked on the side of the road now has a deep dent in its door.
The only logical solution to this problem is to immediately analyze the data with the sensors themselves, or a nearby processing device. They would then be able to react quickly so the safety of the car’s passengers, pedestrians, and surrounding objects can be ensured.
The latency issue is also extremely important in other time-sensitive situations such as emergency response and patient care. In these scenarios, the ability to process data faster can be the difference between life and death.
According to the Cisco Global Cloud Index, the amount of traffic running through cloud computing networks will increase to 14.1 zettabytes per year in 2020.
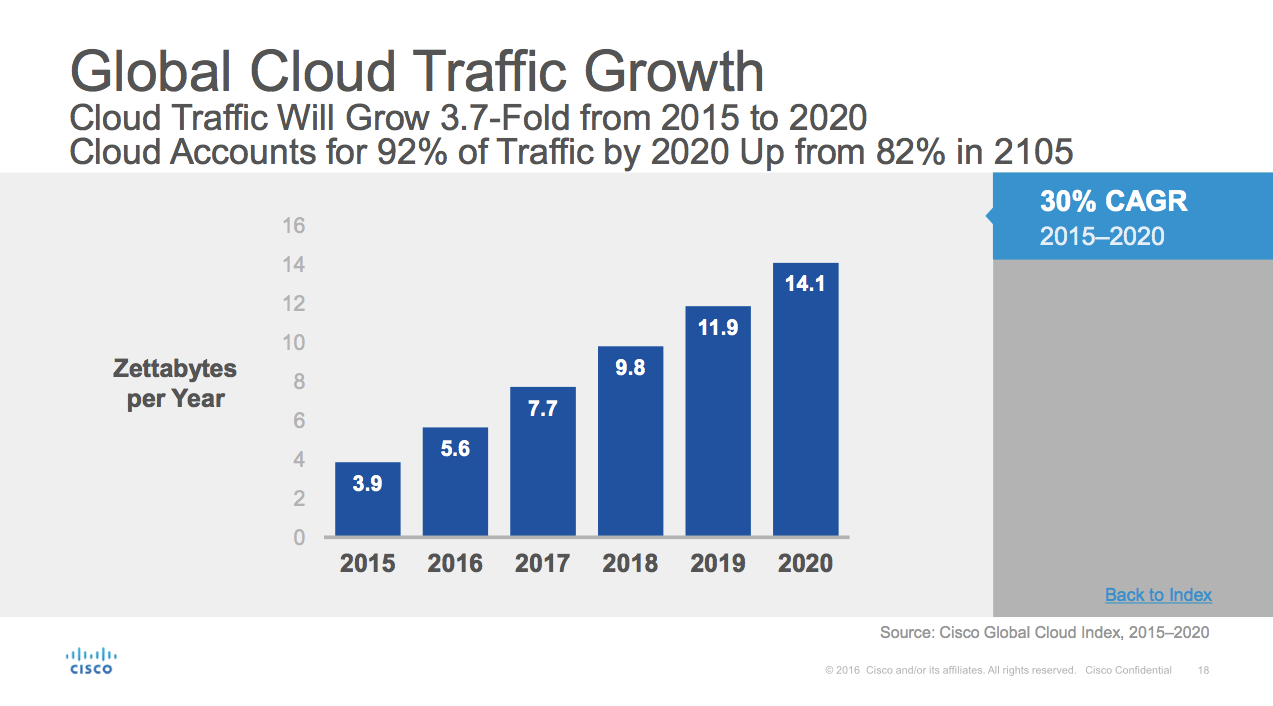
Cloud traffic will grow to enormous amounts. Courtesy of Cisco.
I didn’t even know what a zettabyte is before reading that article. It’s a trillion gigabytes! That’s an unbelievable amount of data and can lead to constrained and poorly-performing networks.
Some of the data-transfer load can be removed from the cloud by processing some of this data closer to where it’s collected.
Additionally, moving the processing of data away from the cloud can help minimize the network load in places where internet connectivity isn’t that strong.
Lower data management costs
Storing large amounts of data in the cloud can be cost prohibitive, and downloading this data from the cloud can have high costs as well.
Additionally, the more data that you transfer to the cloud, the higher bandwidth costs you’ll have to pay.
As the volume of data collected continues to increase, it makes less sense to copy huge amounts of data from one system to another to process and analyze it, if you don’t have to.
Storing and analyzing some of this data at the edge might help cut down on these costs. And only the data that needs to be analyzed in aggregate can be transferred to the cloud.
Other devices and IT assets will remain operational if one fails
The decentralization of computing power that edge networks provide will assure you that if one edge device fails, other nodes and associated IT assets will remain operational.
This is similar to the cloud disaster recovery strategy of using multiple Availability Zones and Regions to ensure that your data and applications aren’t lost in the event of a catastrophe.
Additionally, edge computing can actually be a form of disaster recovery in the case of an internet outage due to a natural disaster.
Improved privacy and security (potentially)
While security used to be a primary concern in moving to cloud computing, that fear has largely subsided.
The concern isn’t so much with the storage of data in the cloud, but more about the transfer of data over a network to the cloud.
Especially in situations where devices collect sensitive personal data such as health metrics or location data, the transmission of this data can have privacy, legal, and security ramifications. And the various regulations in different countries and regions makes this more complicated.
Thus, storing some of this data in or closer to the devices may improve privacy and security.
The other side of the security argument is that the edge devices themselves may be more susceptible to a breach. This may be true, so it’s important that you take steps to ensure the security of your edge devices, such as encrypting your data, tightly controlling access, and securing your networks.
How does edge computing and cloud computing work together?
Even as more data processing and analysis is moved to the edge, cloud computing will still play a big role in making IoT devices smarter and better.
There can be a lot of value in aggregating the data collected locally and analyzing it to come up with overarching insights that can be sent back to and shared across all sensors.
Let’s go back to the Waymo autonomous vehicle example.
By aggregating the data across all of its connected cars and using cloud computing to analyze it, Waymo can create insights and best practices that it can send back to its cars in order to improve their navigation capabilities and optimize car behavior for locations it hasn’t visited before.
GE also offers IoT products for the transportation industry that combine edge and cloud computing.
GE’s sensors are placed on a fleet of trucks to collect data on the performance of the engines, transmissions, batteries, and more. Processing this data at the edge is unnecessary because there isn’t much need for real-time analytics. Instead, all of the vehicle performance data can be aggregated and analyzed in the cloud so trucking companies can receive alerts when parts need to be changed and obtain a fleet-level view of the data to improve maintenance processes and lower repair costs.
The cloud is better suited to perform heavier analyses like looking at historical events and very large datasets. And many times the centralized nature and raw computing power of the cloud outperforms decentralized edge networks in terms of speed, scalability, and costs.
So while edge devices may carry the burden of real-time functional analysis, the cloud will shoulder the load of strategic, high-level insight creation to improve the operation of these devices.
How can you take advantage of the combination of edge and cloud computing?
While edge computing certainly provides many benefits to IoT-based networks, it does add some complexity to architecture and operations.
Here are some of the things you should do to take full advantage of setting up a combination of edge and cloud computing networks.
Define your network architecture
The first thing that needs to be done is to understand your data analysis needs in order to create a network architecture.
If some of your data is going to be processed and analyzed by the devices that collect it (pure edge computing), and the rest will be sent to the cloud for analysis, then it’s a relatively easy architecture.
But if you’re going to apply fog computing, where there may be intermediate nodes between the edge devices and the cloud, then the architecture may be a bit more complicated, like the one below.
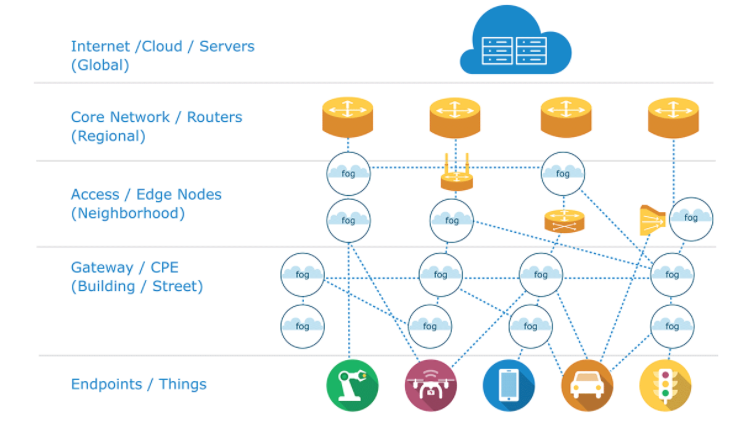
A fog computing architecture can get pretty complex. Courtesy of OpenFog Consortium.
You’ll also have to create a cloud computing architecture that can handle the aggregation and processing of the large amount of data that your IoT network will generate. Setting up the right databases, server types, load balancers, and other cloud components will be important in ensuring an efficient data aggregation and analysis process.
Experient’s AWS architecture
Using a service like AWS Greengrass may help simplify these edge and fog computing architectures. AWS Greengrass allows connected devices to keep data in sync and respond quickly to local events while still using the cloud for storage and analytics. And it’s secured by AWS IoT’s security and access management features.
Policies, policies, policies
After your network architecture has been designed (and eventually implemented), well-defined data policies must be created.
These policies will govern:
There will be many moving parts, so it’s essential that clear policies are laid out to avoid any confusion.
Determine your analytics team, tools, and processes
To take advantage of all of the data you’re collecting, your analytics team, tools, and processes need to be in place.
Some question to ask include:
The data is only as good as the insights that can be gleaned from it. So it’s important to have top-notch data analysts, tools, and processes in place to garner this knowledge.
Conclusion
As IoT becomes more pervasive, edge computing will do the same.
The ability to analyze data closer to the source will minimize latency, reduce the load on the internet, improve privacy and security, and lower data management costs.
The cloud will continue to play a critical role in aggregating important data and performing analyses on this massive set of information to glean insights that can be distributed back to the edge devices.
The combination of edge and cloud computing will help you better manage and analyze your data and significantly increase the value of your IoT efforts.
By Mike Chan