
The success of any Virtual Agent (VA) depends on the training of its Natural Language Understanding (NLU) model prior to configuration. A Major challenge is providing the right set of representative examples from historical data for this training. Identifying a few hundreds of right examples out of millions of historical data is a herculean task. What makes it even more daunting is that this task is usually done by digital service providers (DSPs) manually and it’s extremely time-consuming.
This article articulates about developing a machine-learning (ML) based Intent Analyzer tool to identify the most effective data set for NLU training. These datasets cover maximum scope for the respective intent making to train the NLU model in a highly efficient way which leads to improved precision, recall, and accuracy.
The conventional approach of identifying the training dataset for VA NLU depends heavily on DSP’s internal process experts. It involves choosing the most relevant few hundred examples of millions of historical chat. But it is crippled with inefficiencies because it lacks coverage of all the examples needed for training. Also, it makes way for manual biases and highly time-consuming.
Developing an ML-based intent analyzer tool is the most optimal approach for identifying representative training examples. Below are the steps involved:
Chat logs are sourced as .csv files and imported as data frames using panda’s library. The chat columns are sliced into frames for further processing of data.
It’s an initial cleanup process using regular expressions, followed by refinement of chat-specific components such as chat scripts, time stamps, removal of stop word and punctuation.
TFIDF (Term Frequency Inverse Document Frequency) vectorization is a process to identify the relevance of the word within the context of the document followed by performing stemming to get root (stem) of word sans prefix/suffix.
K-means clustering is performed to identify useful logs. The number of chats (e.g. N= 50) can be specified so that the top N chat logs can be derived. The outcome of the clustering module is to provide the most relevant chats per use case identified.
It involves sourcing historical data from chat logs for respective intents/use cases. Millions of chats are picked and imported to identify the most relevant handful of them.
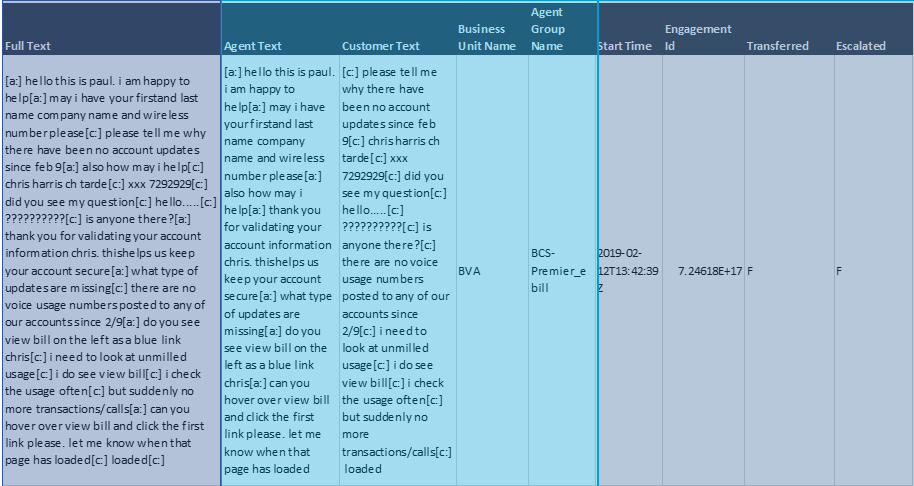
Below figure represent a sample from a template:
The most important parameters to be captured in a template are categorized into three sections
Seasonality in data can lead to wrong inferences. For example, higher call drops or lower speeds during Thanksgiving or Christmas. To reduce the impact, choose the dataset spread over a larger period like 9-12 months.
For efficient separation of metadata, flatten the file into excel file or other simpler formats as shown below
By performing parallel processing and avoiding overloading memory.
The step involves initial cleanup of the chat data by removing chat specific components such as timestamps, stop-words, and punctuations.
Below are some recommendations to be followed during data preprocessing
Below methods can be followed to remove special characters and analyze text at a high level
Removes chat specific notations and special characters which don’t add any value to the analysis. E.g. – timestamps, special characters, etc.
Segregates numerals from alphabets and retains only special strings of alphanumeric values.
Focuses on reducing the words to their root words.
They create noise through their association with other words. They might not be rare, but their usage in a certain context can be misleading. E.g. – revert, captive, hill.
Text vector preprocessing helps in understanding the importance of words as per the relative context. It focuses on the difference in relevance in different circumstances.
Choose a method based on the type of text data. It is recommended to choose ‘term frequency-inverse document frequency (TFIDF) vectorization’ since it considers the relative importance of a word in each context.
TFIDF ensures that the chats are selected according to their relative importance. More than their overall significance in everyday usage, it measures how critical they are in the context of the chat log corpus being analyzed. This helps in identifying the most relevant chats as per the intent. Below techniques are used to increase the accuracy of the outcome from the TFIDF process.
Certain words have an entirely different meanings when used in combination with a few other words. Such words should be configured appropriately.
Tunes the parameters of the vectorization algorithm to optimize the output.
Clustering ensures that the top-N chats (where N is variable depending on business/NLU needs) are derived. These can be quickly analyzed to identify utterances, intents and entities. Additional ML processing such as entity or intent recognition can also be performed if required. All this results in significant time and effort saving.
Choose the technique that can work on huge volume of data like millions of customer chats. It is recommended to use k-means clustering for such a volume.
Ensure one chat is mapped with only one intent i.e. avoid overlapping
Ability to scale the number of top-N use-cases based on intent call-volume (by varying the number of clusters) this enables the number of representative samples to be adjusted based on whether a given intent has more or less volume.
By Sathya Ramana Varri C
Sathya is a Senior Director & heads the AI/ML and Intelligent Automation delivery for the largest US telecom service provider player in US for Prodapt, a global leader in providing software, engineering, and operational services to the communications industry. He has 20+ years of experience spread across various domains/technologies. Sathya is instrumental in several customer experience, intelligent automation & digital transformation initiatives.






